Trefwoord extractie NU.nl - Data | Engineering
Inleiding
Om de personalisatie van de NU.nl app te verbeteren, introduceert dit project een functie waarmee gebruikers zich kunnen abonneren op onderwerpen van interesse. Door de onderwerpen bij te houden waarmee gebruikers zich bezighouden, kan NU.nl op maat gemaakte leestips bieden op basis van individuele voorkeuren en leesgeschiedenis. Bijvoorbeeld, als een gebruiker een artikel leest over een ongeluk in Utrecht, worden onderwerpen zoals “Politie,” “Binnenland,” en “Utrecht” geregistreerd voor toekomstige aanbevelingen.
De Uitdaging van Effectieve Onderwerpidentificatie
Op dit moment vertrouwt het aanbevelingssysteem van NU.nl op handmatig gespecificeerde onderwerpen voor elk artikel. Deze methode kan mogelijk relevante onderwerpen missen. Bijvoorbeeld, een artikel over een dode wolf gevonden in Elspeet wordt getagd met onderwerpen zoals “Dier,” “Wolf,” “Binnenland,” en “Job van der Plicht,” maar mist relevante onderwerpen zoals “Elspeet,” “Gelderland,” en “Politie.” Dit toont de noodzaak aan voor een meer omvattende benadering van onderwerpidentificatie en -categorisering.
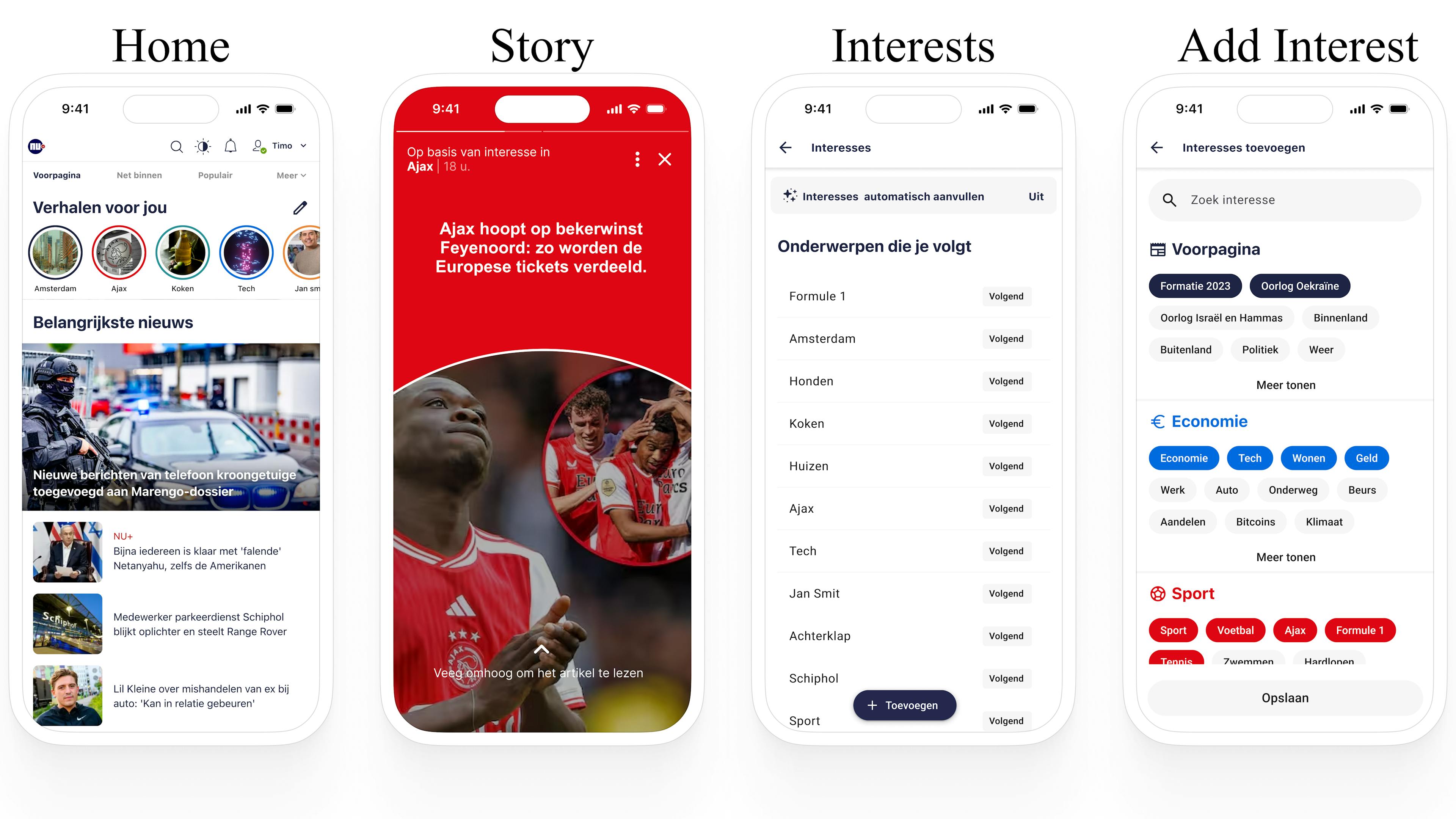
Doelstellingen
Trefwoordextractie
Met behulp van de Natural Language Toolkit (NLTK) is trefwoordextractie gericht op het identificeren van belangrijke woorden of zinnen die de inhoud van een tekst omvatten. Named Entity Recognition (NER) modellen excelleren in het detecteren van entiteiten zoals personen, organisaties en locaties, die cruciaal zijn voor het begrijpen van de context en betekenis van de tekst.
Categoriseren van Trefwoorden
De geëxtraheerde trefwoorden moeten georganiseerd worden in de juiste categorieën om effectief gebruik te garanderen. Deze categorisering wordt bereikt door het gebruik van een Large Language Model (LLM), zoals te zien in Figuur 2 van het technisch rapport.
Fijn-Afstemming van Trefwoorden
Eerdere analyses onthulden verschillende fouten in de trefwoorden, zoals duplicaten, onduidelijke trefwoorden en onjuiste categorieën. Deze problemen worden aangepakt met behulp van een LLM gecombineerd met een mens-in-de-lus methode. Deze aanpak zorgt voor nauwkeurigheid en consistentie in het trefwoordcategoriseringsproces.
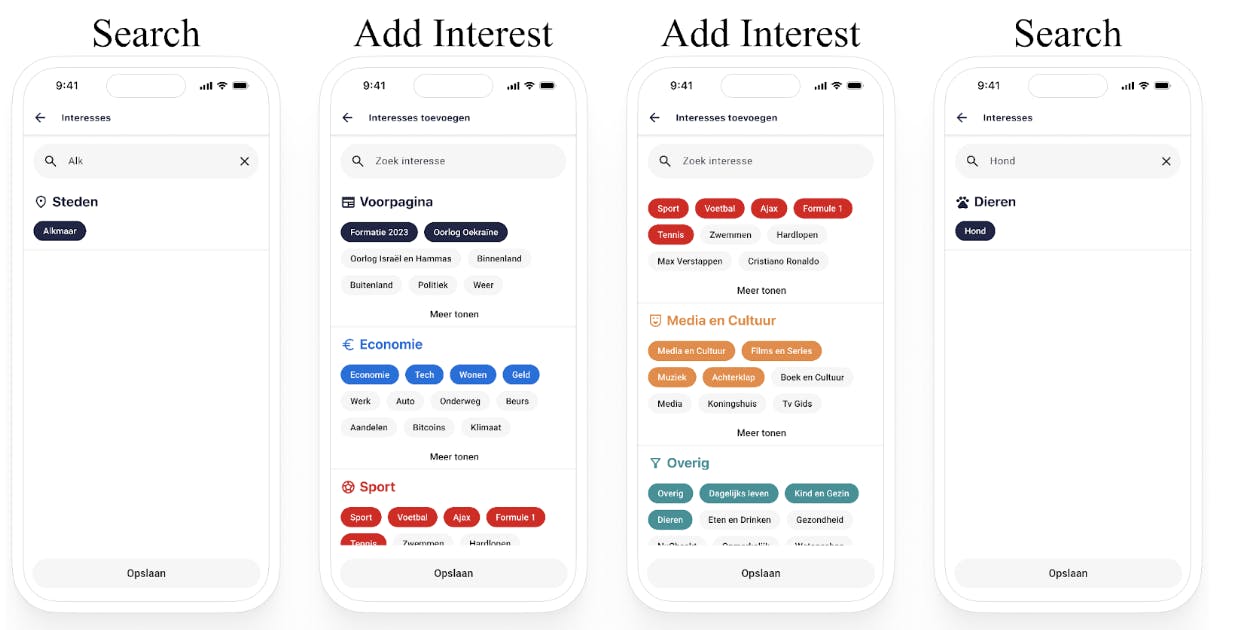
Voordelen
Geautomatiseerde trefwoordextractie is essentieel in nieuwsanalyses voor het begrijpen van trends en onderwerpen over tijd. Handmatige trefwoordextractie is arbeidsintensief en vatbaar voor fouten. Geautomatiseerde technieken die gebruik maken van algoritmes zoals TF-IDF en TextRank maken gebruik van machine learning en statistische algoritmes om significante termen in nieuwsartikelen te identificeren.
Trefwoordextractie uit nieuwsartikelen verbetert de navigatie door documenten, onderwerpdetectie en geautomatiseerde tekstclassificatie. Recent onderzoek heeft ook het gebruik van LLM's in trefwoordfiltering onderzocht om de efficiëntie en nauwkeurigheid van aanbevelingssystemen te verbeteren.
Data
De dataset dat voor dit project is gebruikt, is en zelf gemaakte dataset doormiddel van scraping van NU.nl en bevat 458 verschillende nieuwsartikelen. Het dataset omvat kolommen zoals ID, Titel, Beschrijving, Auteur, Datum, Onderwerp, Tekst en Trefwoorden.
Code
De code voor dit project is beschikbaar op GitHub.
Trefwoordextractie Proces
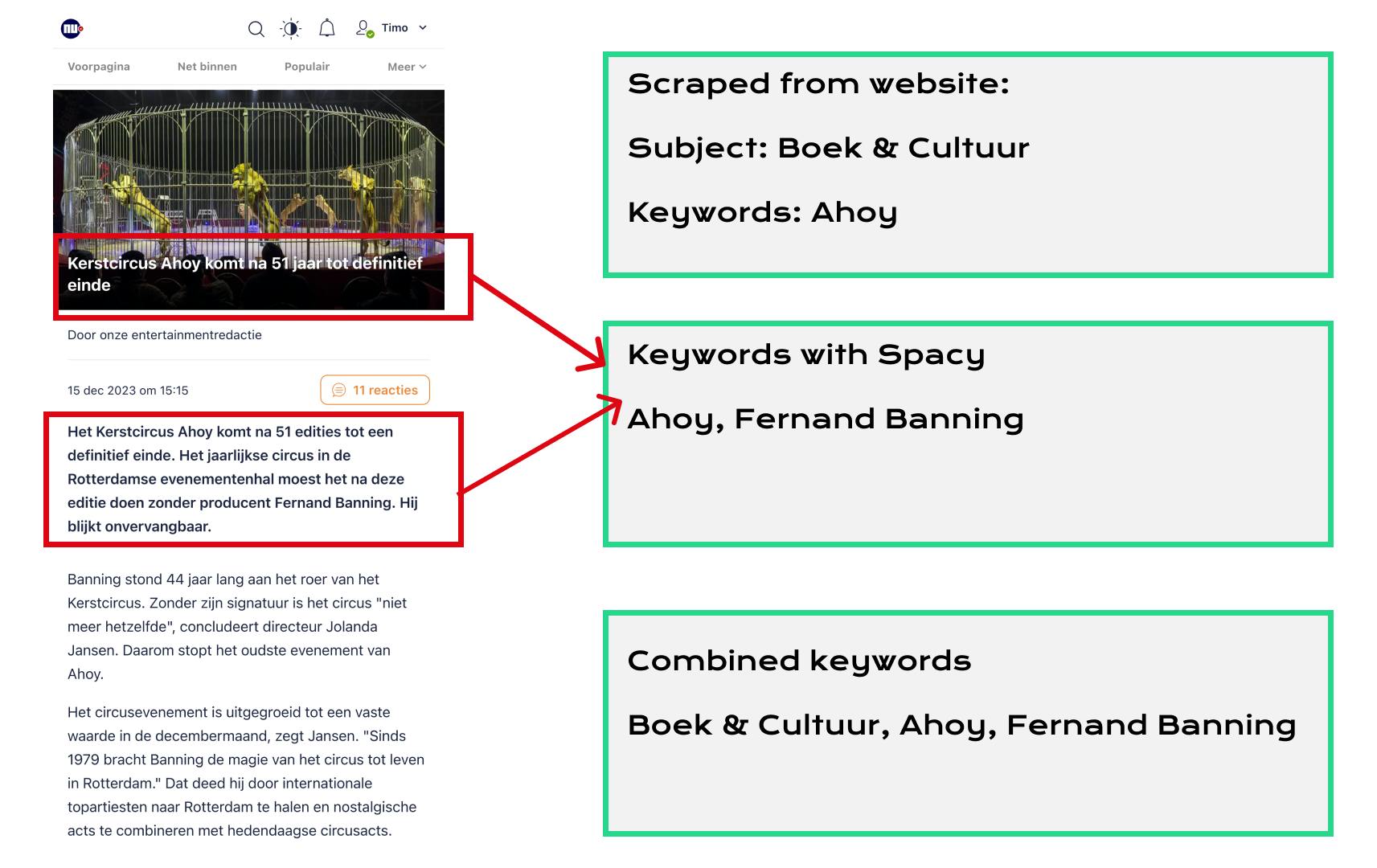
Met behulp van gescrapete data van NU.nl identificeert de extract_keywords functie entiteiten zoals personen, organisaties, locaties, landen en dieren uit de tekst. Het doel is om een gestructureerde aanpak te creëren waarbij het eerste trefwoord het onderwerp is, gevolgd door het samenvoegen van gespecificeerde trefwoorden van NU.nl met de geëxtraheerde, om consistentie te waarborgen.
Problemen en Oplossingen
Problemen zoals dubbele namen, overbodige vermeldingen en spelfouten worden aangepakt met behulp van de OpenAI API voor tekstgeneratie. De get_openai_completion functie roept de OpenAI chat API aan om duplicaten te verwijderen, volledige namen te verkiezen en een door komma's gescheiden lijst van trefwoorden terug te geven.
Trefwoordcategorisering
Alle trefwoorden worden naar de LLM gestuurd voor categorisering. Als de LLM na vijf pogingen geen correcte categorie retourneert, wordt het trefwoord opgeslagen in de "no_category" categorie. De gebruiker beoordeelt alle niet-gecategoriseerde trefwoorden en wijst ze toe aan de bestaande categorieën.

Trefwoordclassificatie
Trefwoorden worden geclassificeerd om relevantie te waarborgen. Irrelevante trefwoorden worden gemarkeerd en door de gebruiker ter controle beoordeeld. De uiteindelijke gecategoriseerde lijst wordt vergeleken met de oorspronkelijke lijst om nauwkeurigheid te waarborgen.

Human-in-the-loop
Er zijn drie Human-in-the-loop processen geïmplementeerd om de trefwoordcategorisering te verifiëren en te verfijnen. Met behulp van Flask in Python is een applicatie ontwikkeld om de JSON-bestanden met de trefwoorden in hun respectieve categorieën te lezen en bij te werken.




Analyse/Prestatie Metrics
Verschillende methoden zoals Levenshtein afstand, clustering, Word2Vec en Woordgelijkenis met spaCy werden gebruikt om trefwoorden met dezelfde betekenis te koppelen. Het gpt-4-turbo model leverde de beste resultaten, hoewel handmatige verificatie noodzakelijk blijft om de nauwkeurigheid van de data te waarborgen.
Conclusie
Het project toont het potentieel aan voor het verbeteren van personalisatie in nieuwsapps door middel van geautomatiseerde trefwoordextractie en -categorisering. Door LLM's te combineren met menselijk toezicht, zorgt het systeem voor nauwkeurigheid en relevantie in de aanbevelingen die aan gebruikers worden gegeven.